一个AI玩41个游戏,谷歌最新多游戏决策Transformer综合表现分
2022-07-24 12:33来源:IT之家 阅读量:14294
谷歌宣布,它在多任务学习方面取得了巨大进展:他们创造了一个可以玩41场雅达利游戏的AI,采用的新训练方法与其他算法相比,大大提高了训练效率!
之前玩星际的CherryPi和火了的AlphaGo都属于单场代理也就是说,一个AI只能玩一局在多智能体方面,现有的训练算法屈指可数:主要包括时间差异学习和行为克隆
但是要让一个代理学会同时玩多个游戏,这些方法之前的训练过程是很漫长的。
现在,谷歌采用了新的决策变压器架构来训练代理,可以在少量的新游戏数据上进行快速微调,使得训练速度更快而且训练效果也是杠杠的——这种多局代理打41场的综合得分是DQN等其他多局代理的两倍左右,甚至比得上只进行单局训练的代理
100%代表每个游戏的平均人类水平,灰条代表单游戏代理,蓝条代表多游戏代理。
让我们来看看这款性能出色的多游戏代理。
新决策转换器的三大亮点
这种处理多种游戏学习的转换器采用了一种将强化学习问题视为条件序列建模的框架它根据agent与环境过去的交互以及预期的收益来指导agent接下来的活动
说到强化学习,讨论的主要问题是:在训练的过程中,面对复杂环境的agent如何在每个时间步感知当前的状态和奖励来指导下一步的行动,从而最终实现累积收益的最大化。
传统的深度RL智能学习一个策略梯度,增加高回报轨迹的概率,降低低回报轨迹的概率。
这就导致了一些问题:需要手动定义一个标量值范围,信息量很大,包括每个具体游戏的适当信息这是一个相当庞大的项目,扩展性很差
为了解决这个问题,谷歌团队提出了一种新方法。
培训包容性数据更加多样化。
谷歌的新决策Transformer将初级玩家到高级玩家的体验数据映射到相应的收入水平开发者认为,这将使AI模型更全面地理解游戏,从而使其更加稳定,提高其游戏水平
根据培训期间代理人与环境之间的相互作用,他们建立了一个利润分配模型这个代理玩游戏的时候,只需要加一个优化偏差,就可以增加高奖励的概率
此外,为了更全面地捕捉训练期间智能体与环境交互的时空模式,开发者还将输入的全局图像改为像素块,使模型能够关注局部动态,掌握与游戏相关的更详细信息。
决策转换器基本架构示意图
可视化代理培训流程
此外,开发人员还别出心裁地将代理的行为可视化然后他们发现,这种多博弈决策智能体总是关注包含关键环境特征等重要信息的区域,它还可以多任务处理:即同时关注多个关键点
红色越亮,代理越关注该像素。
这种多样化的注意力分配也提高了模型的性能。
更好的扩展性。
如今,规模已经成为许多机器学习相关突破的重要驱动力之一,规模扩张一般是通过增加变压器模型中的参数数量来实现的研究人员发现,这种多博弈决策变压器是相似的:伴随着规模的扩大,其性能较其他模型有显著提高
脸书也在研究决策转换器。
Google通过AI使用Decision Transformer,不仅提高了AI玩多游戏的水平,还提高了多游戏代理的可扩展性。
此外,根据谷歌大脑,加州大学伯克利分校和脸书人工智能研究中心的一篇论文,决策变压器架构在加强学习研究平台OpenAI Gym和Key—to—Door的任务方面也表现良好。
也许决策转换器是通用人工智能发展的关键因素之一。
对了,Google AI说相关代码和Checkpoint会陆续在GitHub上开源,有兴趣的朋友可以去看看~
门户网站:
参考链接:
郑重声明:此文内容为本网站转载企业宣传资讯,目的在于传播更多信息,与本站立场无关。仅供读者参考,并请自行核实相关内容。
责任编辑:牧晓
最新阅读
-
![“深交所·创享荟”打造资本市场服务国企改革新典范]()
“深交所·创享荟”打造资本市场服务国企改革新典范
9月27日,深交所举办第九期“创享荟”国企专业化整合专场活动。“创享荟”是深交所着力打造的具有深市特色的市场服务品牌,目前已围绕热点主题举办了多期专场活动,影响力和吸引力不断增强。 深交所相关负...
-
微软在GitHub上线开发工具包,助力开发者使用Rust语言编写Wind
,微软Azure首席技术官MarkRussinovich日前在X平台发文,公开微软最近宣布“扩大采用Rust语言的成果”,微软同时还在GitHub中发布了一系列开发工具包,让开发者可以使用Rust语言...
-
擦亮“金融为民”底色光大银行多维发力谱写“人民金融”新篇章
像这样面向听障人士的手语服务模式,光大银行已持续运行了四年。四年来,光大银行通过收集听障客群金融业务需求及沟通痛点,让金融服务更贴近听障人士的日常生活。而这,只是光大银行践行“金融为民”初心,努力提供...
-
![云南信托联合多家金融机构进乡村开展金融知识普及教育宣传活动]()
云南信托联合多家金融机构进乡村开展金融知识普及教育
近日,为帮助广大农村群众进一步提升金融素养及金融风险防范意识,助力打造诚信、健康、安全、和谐的金融环境,在云南省农村信用社联合社、昆明市农村信用社联合社及昆明市西山区农村信用合作联社的共同协调组织下,...
-
“领头羊”计划走进广州番禺,超59家企业具备上市潜力
南方财经全媒体记者翁榕涛实习生曾日丽广州报道 9月26日下午,广州企业上市“领头羊”行动计划“番禺行动”启动仪式在番禺节能科技园交流中心举行。 据南方财经全媒体记者了解,今年7月以来,广州市地方金...
-
算力牛股中际旭创股价“反攻”800G能否助三季度业绩惯性增长?
21世纪经济报道记者雷晨实习生原婷婷北京报道 近期受国内外AI利好消息驱动,二级市场上,中际旭创股价重新抬头,9月26日、9月27日连续上涨。截至9月27日收盘,公司股价报收于114.07元/股,收...
-
索尼申请外置小型触摸屏专利,可“架在”PS5手柄上远程游玩游戏
,据外媒gamerant报道,索尼近日注册了一项新专利,从文件内容上来看,这项专利主要显示,外加可以使用一个“触摸屏”连接DualSense手柄,来游玩PS5游戏。 图源索尼 索尼于此前正式公布了...
-
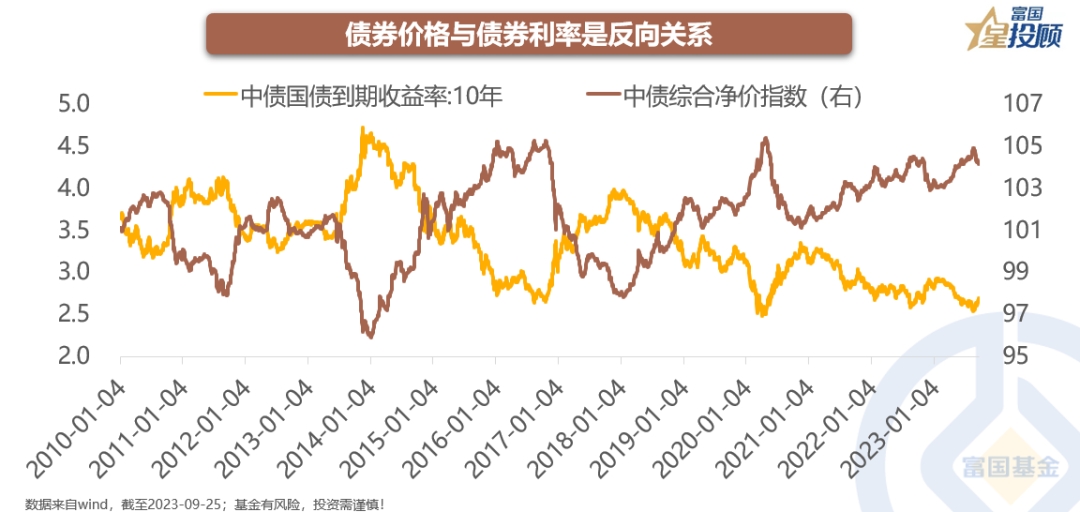
![14幅图看懂债市潮起潮落]()
14幅图看懂债市潮起潮落
超越城乡居民储蓄存款规模和A股总市值,拥有百万亿以上体量的债券。如同资产配置中的“米面粮油”,在投资中无处不在。相较于股票,您可能是更加委婉地参与其中,大部分人是通过银行理财、债券基金、保险、资管计划...
-
国庆黄金周运输今日启动,长三角铁路预计发送超250万人次
国庆黄金周运输启动。 9月27日,澎湃新闻记者从中国铁路上海局集团有限公司获悉,今天是铁路国庆黄金周运输首日,长三角铁路预计发送旅客逾250万人次,较2019年同期多发送60余万人次,增幅超三成。 ...
-
阿里拟分拆菜鸟在港上市菜鸟子公司已申请上百项物流专利
9月26日,阿里巴巴港交所公告,拟通过以菜鸟股份于香港联交所主板独立上市的方式分拆菜鸟。拟议分拆完成后,阿里巴巴将继续持有菜鸟50%以上的股份,菜鸟将仍为其子公司。 天眼查App显示,菜鸟网络科技有...